1.前言
時隔 2 個月,終於有繼續更新了blog,這兩個月忙於大專案的上線,但自己還算可以從容應對.今天要來分享一個我一直很感興趣的主題 Kubernetes(K8s)。傳統部署的煩惱是每次上線都要排在半夜、提前公告維護視窗、祈禱不要出事,那如何打造一個良好的部署策略,將會是本文的重點。就讓我們用真實專案的部署流程,展示如何實現「推 code → 自動上線,用戶無感」。
2.背景知識
如果你有閱讀過我的工作2個月心得-部署策略與資安洩漏 ,裡面有提到多種的部署策略,而其中最不易被用戶察覺的就是「 滾動部署 」。
2-1. 什麼是零停機部署(Zero-Downtime Deployment)?
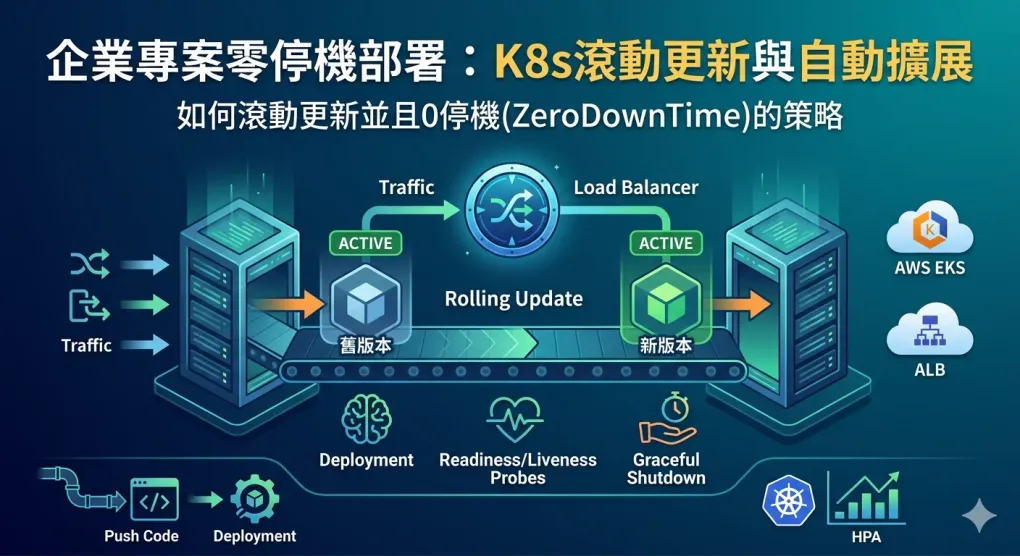
定義:新版本上線期間,舊版本持續服務請求,不出現 502/503
2-2. 零停機的三個必要條件
| 條件 | 說明 |
|---|---|
| 新 Pod 健康才接流量 | readinessProbe |
| 舊 Pod 優雅退場 | preStop + terminationGracePeriodSeconds |
| 資料庫遷移不鎖表 | migration job 先跑、向前相容 |
3.K8s 核心概念介紹
3-1. Deployment — 管理 Pod 的大腦
# deployment.yaml 節錄
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0 # 保證服務不中斷
maxSurge: 1 # 最多多開 1 個新 PodmaxUnavailable: 0→ 永遠有 Pod 在服務中maxSurge: 1→ 更新時暫時多跑一個新版 Pod,確認健康才殺舊的
3-2. 偵測探針(Readiness) vs 存活探針(Liveness Probe)
readinessProbe: # 就緒探針:Pod 準備好才接流量
httpGet:
path: /health
port: 8000
initialDelaySeconds: 5 # 啟動後等 5 秒再開始探測
periodSeconds: 5 # 每 5 秒探測一次
failureThreshold: 3 # 連續失敗 3 次才標記為未就緒
livenessProbe: # 存活探針:Pod 卡死時自動重啟
httpGet:
path: /health
port: 8000
initialDelaySeconds: 10 # 給更多時間完成初始化
periodSeconds: 10 # 每 10 秒探測一次
failureThreshold: 3 # 連續失敗 3 次才重啟 Pod- readiness:Pod 還沒 ready 就不接流量(零停機的核心)
- liveness:Pod 卡死了就重啟(避免殭屍 Pod)
- 兩者分開設定的原因:啟動慢不代表需要重啟
3-3. 優雅退場(Graceful Shutdown)
lifecycle:
preStop:
exec:
command: ["sleep", "5"]
terminationGracePeriodSeconds: 30- K8s 刪除 Pod 的流程:
SIGTERM→preStop hook→ 等待連線完成 →SIGKILL sleep 5:給 ALB 足夠時間把這個 Pod 從目標群組移除,避免 in-flight 請求被切斷
3-4. Service 與 Ingress
- Service:集群內部 L4 負載均衡,穩定的 ClusterIP 讓 Ingress 打得到
- Ingress + AWS ALB Controller:對外入口,
target-type: ip直打 Pod IP,效能更好 deregistration-delay: 10s:ALB 等 10 秒讓舊連線排空才下線 target
4.零停機為何能成立?完整時序
用一張流程圖說清楚:
Push code
→ Bitbucket Pipeline 觸發
→ Step 1: Build Docker image,打上 commit hash tag,push 到 ECR
→ Step 2:
1. kubectl apply manifests(ingress, secrets...)
2. 執行 Alembic migration Job(等待成功)
3. 執行 seed Job(等待成功)
4. kubectl set image → 觸發 Rolling Update
- K8s 啟動新 Pod
- readinessProbe 通過後,ALB 才把流量導入新 Pod
- 舊 Pod 收到 SIGTERM → preStop sleep 5s → graceful shutdown
5. kubectl rollout status(等待完成或 timeout 300s)
→ 若失敗:after-script 自動 kubectl rollout undo關鍵:整個過程用戶請求始終有 Pod 接著,沒有空窗期
5.EKS 與原生 K8s 的差別
| 面向 | 原生 K8s(自架) | AWS EKS |
|---|---|---|
| 控制平面 | 自己維護 etcd、kube-apiserver | AWS 全託管,SLA 99.95% |
| 節點認證 | 手動設定 kubeconfig | IRSA(IAM Roles for Service Accounts) |
| 密鑰管理 | 自己接 Vault 或 base64 Secret | External Secrets Operator + AWS Secrets Manager |
| 負載均衡 | 自己裝 ingress-nginx | AWS Load Balancer Controller → 自動建 ALB |
| 儲存 | 手動掛 NFS/Ceph | EBS/EFS CSI Driver |
| 費用模型 | 只有機器費 | 額外 EKS cluster 費 + AWS 服務費 |
5-1. IRSA — 不需要在程式碼裡放 AWS 金鑰
Pod 啟動時自動拿到 temporary credentials,可以直接呼叫 Secrets Manager、S3 等服務
6.CI/CD Pipeline 設計邏輯
6-1. 雙環境策略
dev branch→ 自動 build + 自動 deploy(快速迭代)master branch→ 自動 build + 手動確認才 deploy(production 保護)
6-2. Image 打兩個 Tag 的原因
docker tag $ECR_REPO:$IMAGE_TAG $ECR_REPO:latestcommit hash:精準回溯,rollout undo 或 rollout history 能對到具體版本latest:方便臨時 debug 或本地 pull 最新版
6-3. Migration 先於 Deploy 的重要性
migrate Job → 成功 → deploy(新版 API 上線)
↘ 失敗 → Pipeline 中止,舊版 API 繼續服務- 向前相容設計(expand/contract pattern):新欄位先 nullable,讓新舊版本能同時運作
ttlSecondsAfterFinished: 3600:Job 完成後 1 小時自動清理,不塞 API server
6-4. 自動 Rollback
# after-script(Pipeline 失敗時執行)
if [ $BITBUCKET_EXIT_CODE -ne 0 ]; then
kubectl rollout undo deployment/your-app
fi7.常見 kubectl 指令速查
# 查看 Deployment 狀態
kubectl get deployment your-app
kubectl describe deployment your-app
# 查看 Pod 狀態與事件
kubectl get pods -l app=your-app
kubectl describe pod <pod-name>
kubectl logs <pod-name> --tail=100 -f
# 滾動更新相關
kubectl rollout status deployment/your-app
kubectl rollout history deployment/your-app
kubectl rollout undo deployment/your-app # 回上一版
kubectl rollout undo deployment/your-app --to-revision=3 # 回指定版本
# 手動更新 image
kubectl set image deployment/your-app api=<ecr-repo>:<new-tag>
# 查看 Job 執行結果
kubectl get jobs
kubectl logs job/migrate-<short-sha>
# 強制重啟(不改 image,用於 config 更新)
kubectl rollout restart deployment/your-app
# 查看 Ingress 與 Service
kubectl get ingress
kubectl get svc your-app8.結語
- 架構限制:
replicas: 1在滾動更新期間surge=1短暫跑兩個 Pod,成本可接受但不適合有強狀態的服務 - 未來擴展:可加上 HPA(Horizontal Pod Autoscaler)根據 CPU/請求量自動擴縮
- 最終心得:零停機不是魔法,是 readinessProbe + graceful shutdown + 相容性 migration 三個習慣的疊加


